
Najważniejszym założeniem tego wpisu jest zapoznanie się z architekturą technologii Hadoop. Zatem bez zbędnych treści, czas się z nią oswoić.
- HDFS
- YARN
- MapReduce
Mówiąc o Hadoopie na myśl powinien od dziś przychodzić jego główny rdzeń, którego budują:
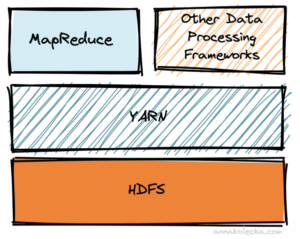
HDFS (Hadoop Distributed File System) czyli rozproszony system plików w architekturze master-slave a przede wszystkim przedstawiciel storage, który przechowuje dane na maszynach.
MapReduce – silik, ale też i jednocześnie framework, którego zadaniem jest wykonywanie obliczeń danych składowanych w HDFS.
YARN (Yet Another Resource Negotiator) pełni funkcję swojego rodzaju nakładki na MapReduce, zarządza zasobami komputerowymi w klastrach a tym samym wykorzystuje je w zadaniach użytkowników. To architektoniczne centrum efektywnego wykonywania operacji Hadoop z użyciem różnych przewidzianych do tego dialektów języka i frameworków. Dodatkowo YARN nadzoruje i wyłapuje wszelkie anomalie, a każde zweryfikowane niepowodzenie, zleca na inne maszyny.
Wszystkie te elementy współpracują ze sobą tworząc wydajny klaster obliczeniowy ogólnego przeznaczenia.
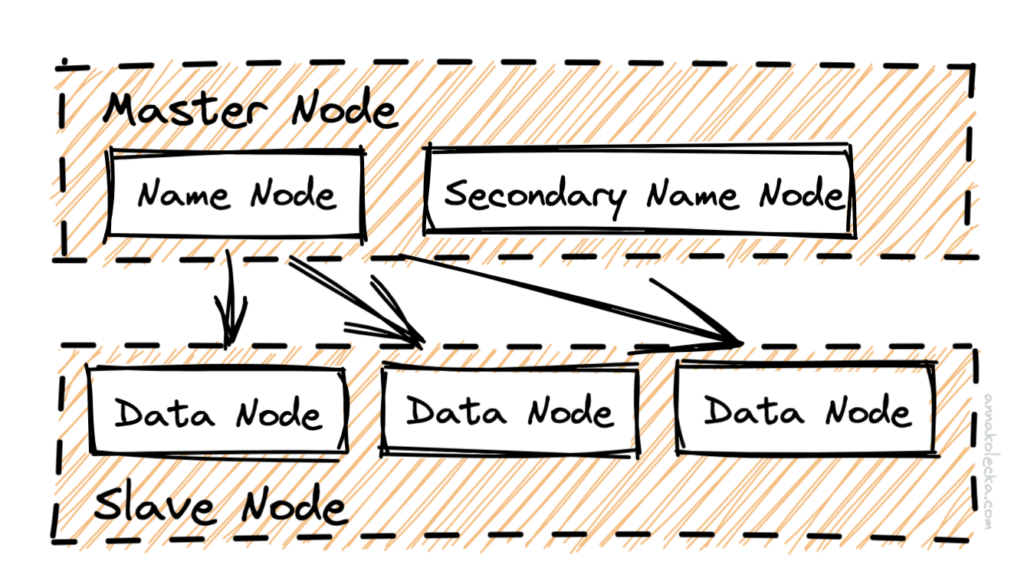
Poniższy diagram przedstawia logiczne komponenty systemu plików HDFS:

Analizując strukturę szerzej, warto mieć na uwadze, że zamieszczone w węzłach usługi dzielą się między sobą odpowiednio na te przechowujące dane, oraz te, które te dane analizują, odczytują, zapisują i usuwają. Tak więc do grupy tych pierwszych należą bloki danych, replikacje, punkty kontrolne i metadane plików natomiast grupa zarządzająca dotyczy NameNode, DataNode i JournalNode.
Istotne w modelu są również takie byt jak Resource Manager, który zarządza zadaniami ze wszystkimi aplikacjami w klastrze oraz Node Manager będący agentem dla poszczególnych węzłów, odpowiedzialnym za kontenery i zużycie zasobów, tj. sieci, procesorów, pamięci operacyjnej, dysków.
Porozmawiajmy wpierw o grupie zarządzającej…
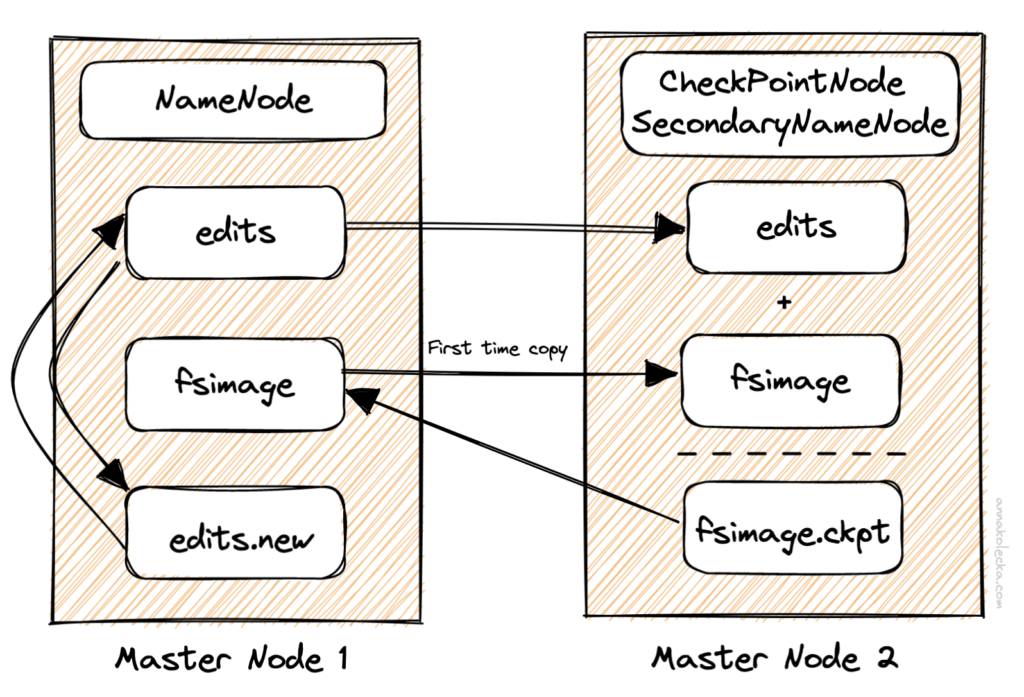
NameNode – pełni on rolę mastera w architekturze HDFS stąd odpowiedzialny jest za przechowywanie informacji o rozmieszczeniu bloków w klastrze. Ponadto zarządza przestrzenią nazw systemu plików a wszelkie informacje są przechowywane na dysku lokalnym opierając się na trzech typach, mianowicie: plikach fsimage, plikach obrazowych oraz dziennikach edycji. Fsimage przechowuje stan systemu plików w zadanym momencie. Gromadzi on listę wszystkich zmian tzn. tworzenia, modyfikowania czy usuwania, którym zostały poddane pliki HDFS.
Zgodnie z przedstawionym poniżej schematem nowy fsimage jest kreowany na podstawie punktów kontrolnych czyli procesu łączenia zawartości najnowszych fsimage z najnowszymi dziennikami edycji. Jest on wyzwalany przez system i zarządzany zgodnie z obowiązującymi zasadami.
Warto dodać, że NameNode utrzymuje również mapowanie wszystkich bloków danych do DataNode, czyli bytu który pełni funkcję slave w architekturze HDFS. Wykonuje on operacje na blokach danych według uzyskanych instrukcji od klientów NameNode czy HDFS. Co więcej, obsługuje on zadania związane z przetwarzaniem danych czyli wspomniany na wstępie MapReduce.
JournalNode – swoją obecnością gwarantuje istnienie blokady współbieżnego zapisu. To kluczowe zadanie dzięki, któremu mamy pewność, że dzienniki edycji są zapisywane przez jeden aktywny NameNode na raz. Ten poziom kontroli współbieżności jest wymagany, aby uniknąć sytuacji, w której stan węzła NameNode jest zarządzany przez dwie różne usługi, działające jednocześnie w trybie failover.
Grupa przechowującą dane, czyli…
Bloki danych – określają minimalną ilość danych, które system HDFS może jednocześnie odczytywać i zapisywać.
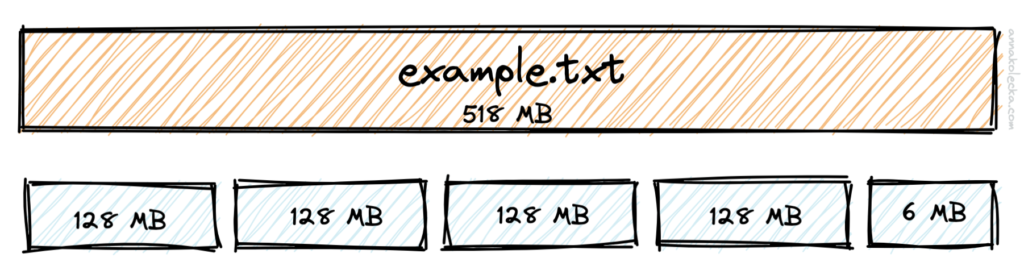
HDFS podczas przechowywania dużych plików dzieli je na zestawy pojedynczych bloków i przechowuje każdy z tych bloków w różnych węzłach. Domyślna wartość rozmiaru bloku to 128 MB i już w samym posiadaniu dużego rozmiaru można dopatrywać się korzyści, ponieważ zapewnia to efektywne zarządzanie metadanymi powiązanymi z każdym blokiem danych. W sytuacji jeśli mamy do czynienia ze zbyt małym rozmiarem bloku, w NameNode będzie to skutkowało przechowywaniu większej ilości metadanych a tym samym przyczyni się to do szybkiego zapełnienia pamięci RAM.
Ideą HDFS jest równoległy odczyt, co znacząco przyspiesza operację na danych zatem plik składający się z kilku bloków łatwiej się odczytuje, gdyż żądanie odczytu tego zasobu jest realizowane równolegle na tych węzłach, na których zostały ulokowane bloki tego pliku.
Replikacja HDFS – wpływa tak naprawdę na wszystkie dobrodziejstwa uzyskiwane z tytułu wykorzystywania HDFS czyli niezawodność, skalowalność i wydajność. Domyślnie HDFS ma współczynnik replikacji równy trzy, dlatego autorzy technologii Hadoop zadbali o to gdzie powinna być umieszczona każda replika bloku danych. Jest to wynikiem ustalonej polityki, która zakłada, że awarie szafy serwerowej są mniej prawdopodobne niż awarie węzłów. Blok jest umieszczany tylko w dwóch różnych szafach, a nie w trzech, co zmniejsza prawdopodobieństwo wykorzystania przepustowości sieci. Jeśli chodzi o maksymalną liczbę replik, którą można uzyskać w HDFS, to jest uwarunkowana od liczby DataNode z uwagi na to, że sam DataNode nie może przechowywać wielu kopii tego samego bloku. HDFS zawsze próbuje kierować żądania odczytu bezpośrednio do repliki znajdującej się najbliżej klienta, stąd jeśli węzeł znajduje się pod tym samym rackiem, w którym znajduje się replika, to jest on przypisany do odczytu bloku. Jeśli współczynnik replikacji jest większy niż domyślny współczynnik replikacji, który wynosi trzy, wówczas czwarta i kolejne repliki są umieszczane losowo, zgodnie z limitem replik na szafę.
Jak to się wszystko teraz tak naprawdę ze sobą komunikuje?
Poznaliśmy właśnie budowę HDFS więc teraz pora zrozumieć podstawy jego procesu komunikacji, który odbywa się za pośrednictwem protokołu TCP/IP.
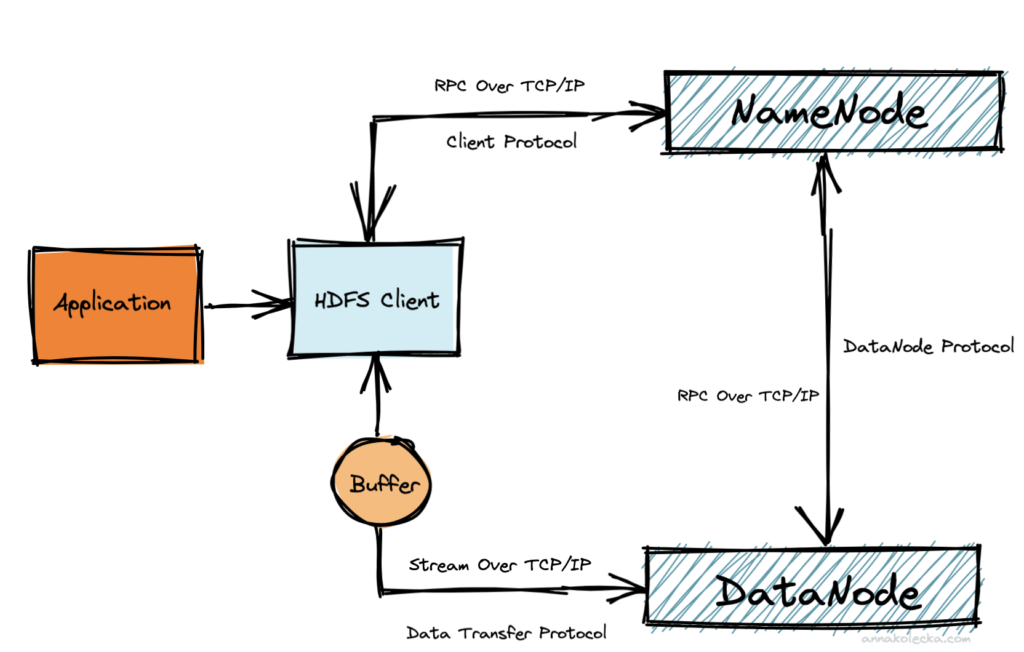
Client Protocol jest, jak sama nazwa wskazuje, jest protokołem zdefiniowanym dla realizowania celów komunikacji między klientem HDFS a serwerem NameNode przy użyciu zdalnego wywołania procedury RPC. Ważnymi metodami utożsamianymi z tego rodzaju protokołem są:
- create – tworzenie nowego pliku w przestrzeni nazw HDFS.
- setReplication – ustawianie replikacji pliku.
- addBlock – zapisywanie dodatkowych bloków danych do plików wraz z węzłami danych do replikacji.
Od chwili kiedy to klient HDFS wejdzie w posiadanie informacji na temat metadanych przekazanych od NameNode, kolejno nawiązuje komunikację z DataNode w celu odczytu i zapisu tych danych. Jest to typ komunikacji zdefiniowany przez kolejny byt wyżej przedstawionego schematu – Data Transfer Protocol, który jest bardzo istotnym protokołem definiującym zarówno przebieg odczytu i zapisu między klientem a węzłem danych. W tej sekcji typu protokołu biorą udział metody takie jak:
- readBlock – odczytywanie bloku danych z DataNode.
- writeBlock – zapisywanie bloku danych w DataNode.
- transferBlock – transferowanie bloku danych między dwoma DataNode.
Kolejnym protokołem o którym należy wspomnieć jest Data Node Protocol. Jednym z ważnych aspektów tego protokołu jest to, że jest on jednokierunkowy co jest równoznaczne z tym, że wszelkie żądania są zawsze inicjowane przez DataNode natomiast NameNode odpowiada tylko na żądania inicjowane przez DataNode. Warto również i tu wspomnieć o kilku najważniejszych metodach, które zostają powoływane, czyli:
- registerDatanode – rejestrowanie lub uruchomianie węzłów danych w NameNode.
- blockReport – wysyłanie przez DataNode wszystkich przechowywanych lokalnie informacji związanych z blokami do NameNode. W odpowiedzi na to wszelkie przestarzałe bloki NameNode wysyła do DataNode, celem ich finalnego usunięcia.
Podsumowanie
O architekturze można mówić zdecydowanie dłużej i szerzej. Zanim jednak postawimy swój pierwszy klaster warto nabrać większej świadomości. Zachęcam aby po zapoznaniu się z podstawami, zagłębiać dalej wiedzę związanej z tą technologią szczególnie u samego źródła – https://hadoop.apache.org/