
Żyjemy w czasach wielkich danych (eng. big data), generowanych w, niemalże, każdym zakątku otaczającej nas przestrzeni. Taki stan rzeczy jest konsekwencją pojawienia się szeregu nowych technologii i obszarów działań, do których zaliczają się między innymi: telefon komórkowy, sieci społecznościowe czy ogólnie Internet.
Nowy model świata wywołał jednak największe zamieszanie w środowisku informatycznym, które swoją działalność opiera między innymi na zdobywaniu i wykorzystywaniu umiejętności przetwarzania ogromnych ilości informacji, podejmowaniu decyzji oraz na poszukiwaniu coraz to nowszych i bardziej wydajnych sposobów analizy czy przechowywania zbiorów. Można więc śmiało stwierdzić, że branża ta nie śpi.
W ciągu ostatnich kilku lat pojawiło się wiele rozwiązań, którym niestraszne są te ogromne ilości danych. Mowa tu w szczególności o nierelacyjnych rozwiązaniach bazodanowych, czyli tzw. NoSQL czy choćby ekosystemie Hadoop będącym otwartą platformą do przechowywania nawet i petabajtów informacji. I tak od literki do słowa, od wyrazu do końca tego wstępu, przyszła pora na poznanie narzędzia o wdzięcznej nazwie ElasticSearch.
Trochę teorii
ElasticSearch jest rozproszonym silnikiem wyszukiwania oraz narzędziem do eksploracji i analizy danych tekstowych w czasie niemal rzeczywistym, który stanowi jednocześnie serce całego Elastic Stack’a funkcjonującego również pod akronimem ELK. Pomysłodawcą tego przedsięwzięcia jest firma Elastic, a w swoim pakiecie, poza ElasticSearch’em, oferuje nam w szczególności dwa równie ciekawe i kluczowe rozwiązania odpowiadające na zapotrzebowanie przetwarzania logów aplikacji wraz z możliwością zarządzania nimi w sposób scentralizowany, czyli Kibana i Logstash.
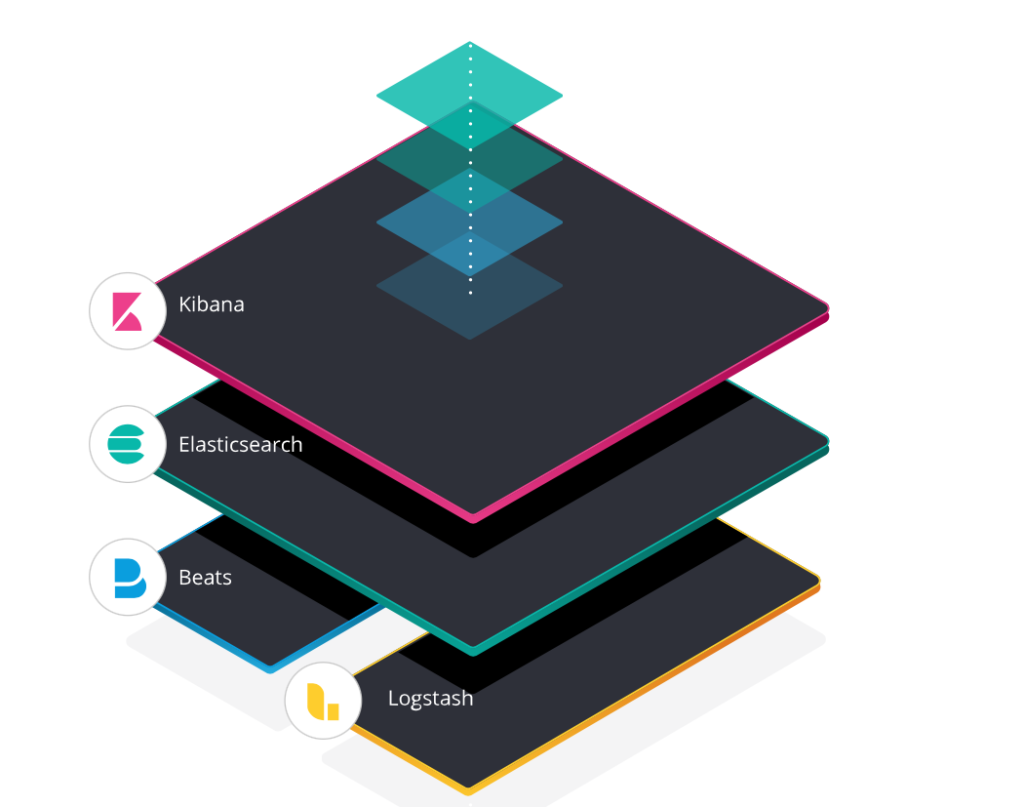
źródło: www.elastic.co
Kibana, jest swojego rodzaju oknem na sam Elastic Stack. Innymi słowy, jest to narzędzie, które służy do wizualizacji danych gromadzonych w ramach ElasticSearch’a. Niewątpliwie sprosta ona także tworzeniu wszelkich wykresów czy też świetnie sprawdzi się jako interfejs pełniący funkcję monitoringu danego klastra.
Jej kompan, Logstash, natomiast jest takim pudełkiem o potężnych możliwościach, do którego trafiają logi z różnych źródeł w celu ich przetworzenia i wydobycia interesujących nas informacji.
W gruncie rzeczy warto też pokrótce wspomnieć o innych produktach — choćby tych ukrywających się pod nazwą X-Pack czy Beats. Pierwszy z nich jest rozszerzeniem dla całego „elastycznego stosu”. Powierzone zostały mu zadania związane z zapewnieniem bezpieczeństwa, monitorowaniem, tworzeniem raportów czy uczeniem maszynowym. Drugi zaś skupia się na wyłapywaniu zdarzeń, które dokonały się na plikach czy pakietach sieciowych, by czym prędzej powiadomić o tym fakcie swoich towarzyszy — Logstash’a i ElasticSearch’a. Mimo że firma Elastic utworzyła kilka autorskich beatsów, to jednak nie sposób pominąć istotnego faktu, iż dała możliwość tworzenia własnych i dzielenia się nimi w całej społeczności.
Natomiast o bohaterze tego wpisu należy powiedzieć znacznie więcej, niż zamieszczone na wstępie zdanie, ponieważ z własnego doświadczenia wiem, że pierwsze kroki bywają trudne i nieco skomplikowane dla żółtodziobów. Finalnie jednak utwierdzam się w przekonaniu, że jest on przyjemnym narzędziem, do którego podobieństw upatrywać można w MySQL, PostgreSQL czy rozwiązaniach NoSQL. Jak się okazuje, nie bez powodu, ElasticSearch bowiem jest bazą danych, jednak po prostu taką nadzwyczajną.
Za tym sukcesem stoi wspomniany fakt oparcia tej technologii o model rozproszony oraz wykorzystanie w swojej strukturze Apache Lucene. Zaraz, zaraz… Skoro więc za podstawą kryje się otwartoźródłowa (eng. OpenSource) biblioteka, która oferuje właśnie funkcje wyszukiwania, zbierania, indeksowania, po co ten cały ElasticSearch?
Spieszę zatem z odpowiedzią. Otóż między Apache Lucene a tworem na jego bazie istnieje różnica, można by rzec, na korzyść tego drugiego. ElasticSearch udostępnia nam REST API, dzięki czemu można w bardzo prosty i przyjemny sposób używać tego narzędzia z wykorzystaniem dowolnej technologii. Wydaje się to już mniej skomplikowane?
Budowa
Oczywiście na tym nie kończy się lista zalet. By w pełni poznać możliwości, jakie kryją się w ElasticSearch’u i przejść świadomie do praktyki, warto najpierw poznać jego elementarną budowę. W myśl, że najlepiej wychodzi rozumowanie od ogółu do szczegółu, tak więc i ja posłużę się teraz tą pradawną zasadą, zaczynając od… Klastra.
Klaster (eng. cluster) jest zbiorem węzłów, które dołączają do jego szeregów na podstawie atrybutu cluster.name będącego unikalną nazwą. Podczas występowania tego procesu, klaster sam automatycznie się reorganizuje, aby w sposób równomierny dokonać podziału danych na dostępne węzły. Czym w takim razie jest wspomniany węzeł?
Otóż węzeł (eng. node) jest pojedynczym serwerem. Co ciekawe, jeden węzeł w ramach klastra dostaje miano węzła nadrzędnego. Nowa rola związana jest z posiadaniem pełnej odpowiedzialności zarządzania zmianami, tworzeniem bądź usuwaniem innego węzła czy indeksu.
Indeks (eng. index) natomiast jest jak relacyjna baza danych. To miejsce służące do gromadzenia informacji oraz realizowania działań związanych z wyszukiwaniem kolejnych dokumentów (eng. document). Są to niejako rekordy dla naszej bazy danych, przechowywane w zdefiniowanym schemacie JSON.
W rzeczywistości indeks jest tylko pewnego rodzaju logiczną przestrzenią, a nasze dane tak naprawdę są przechowywane i indeksowane w miejscu określanym fragmentem, bądź łuską (eng. shard). Na wstępie wystarczy jedynie wiedzieć, że jest to pojedyncza instancja Apache Lucene, oraz że odpowiada za dbanie o operacje dyskowe czy analizę tekstu.
Ostatnim pojęciem, o którym należy wspomnieć, jest replika (eng. replica), czyli specjalna odmiana sharda, która odgrywa równie istotną rolę w całej omawianej strukturze. Jako że jest to szczególna łuska, tak też otrzymała szczególne zadanie: duplikuje bowiem dane na wypadek pewnych awarii i nieprzewidzianych problemów.
Ciekawostka:
Do wersji 7.0.0 obowiązywała też jednostka zwana typem (eng. type). Była ona swojego rodzaju poziomem grupowania, do którego analogii można dopatrywać w relacyjnej bazie danych pod postacią tabeli. Została ona jednak wycofana z użytkowania ze względu na wprowadzanie w błąd użytkowników, jeśli chodzi o proces przechowywania czy kategoryzowania dokumentów.
Podsumowanie:
ElasticSearch to godna uwagi technologia, która umożliwia przeprowadzanie procesów wyszukiwania pełnotekstowego czy analizy danych. Odpowiednie modelowanie danych, konfiguracja i monitorowanie klastra, a finalnie przeprowadzenie wdrożenia w poprawny i wolny od błędów sposób zapewnia uzyskanie szeregu zalet w trakcie użytkowania. Jednak pomimo plusów, jak każda technologia posiada ona również pewne wady, które tak naprawdę da się zdefiniować i odkrywać wykorzystując ją w praktyce.